記事のターゲット
- Pythonでよく聞くスクレイピングをやってみたい人
- Pythonで何かしらそれっぽいことをやってみたい人
筆者の環境
・Jupyter Notebook (anaconda3)
スクレイピングとは
簡単に言うとウェブサイトから好きな情報を持ってくることです。
指定したウェブサイトのURLさえ知っていればそのサイトの画像や文章等を取得することができます。今回はそのさわりの部分を紹介します。
ただし、禁止しているサイトも多く、所かまわずスクレイピングすると逮捕されてしまうこともあるので注意が必要です。もし実行する場合はきちんとサイトのプライバシーポリシー等で確認しましょう。
手順
step
1事前にダウンロードするもの
今回事前準備でダウンロードするものは2つあります。1つ目はrequestsというライブラリでもう一つはBeautiful Soupというものです。
・requests → サイトの情報取得
・Beautiful Soup → 取得したサイト内の検索
のようなイメージで大丈夫だと思います。
pip3 install requests
pip3 install beautifulsoup4上記のコマンドを自身のコマンドプロンプト等で実行してください。わからなければスタートキー→anaconda Promptと入力→出てきたプロンプトをクリックで開けます。
requestsの方はもともとインストールされている場合もあります。
step
2実際に取得してみる
今回情報はこのサイト内から取得しようと思います。
まずは下記のコードを実行してみます。
import requests
r = requests.get('https://begi-tech.com/')
print(r.headers)
print(r.encoding)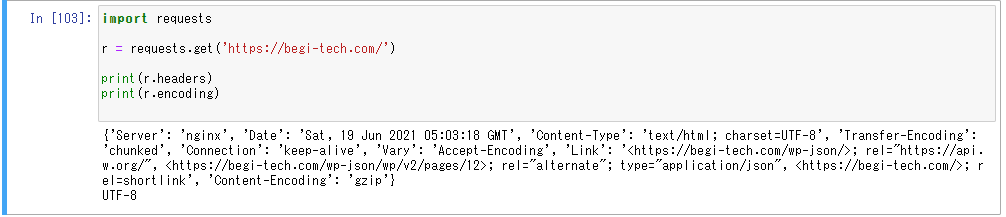
すると上記のようにサイトの情報を取得することができます。ただこのままだと特に使えないのでさらに発展させていきます。
取得したサイトの情報を基にさらにデータを取得してみます。
import requests
from bs4 import BeautifulSoup
r = requests.get("https://begi-tech.com/")
soup = BeautifulSoup(r.content, "html.parser")
[tag.text for tag in soup.find_all('a')]これを実行してみると、
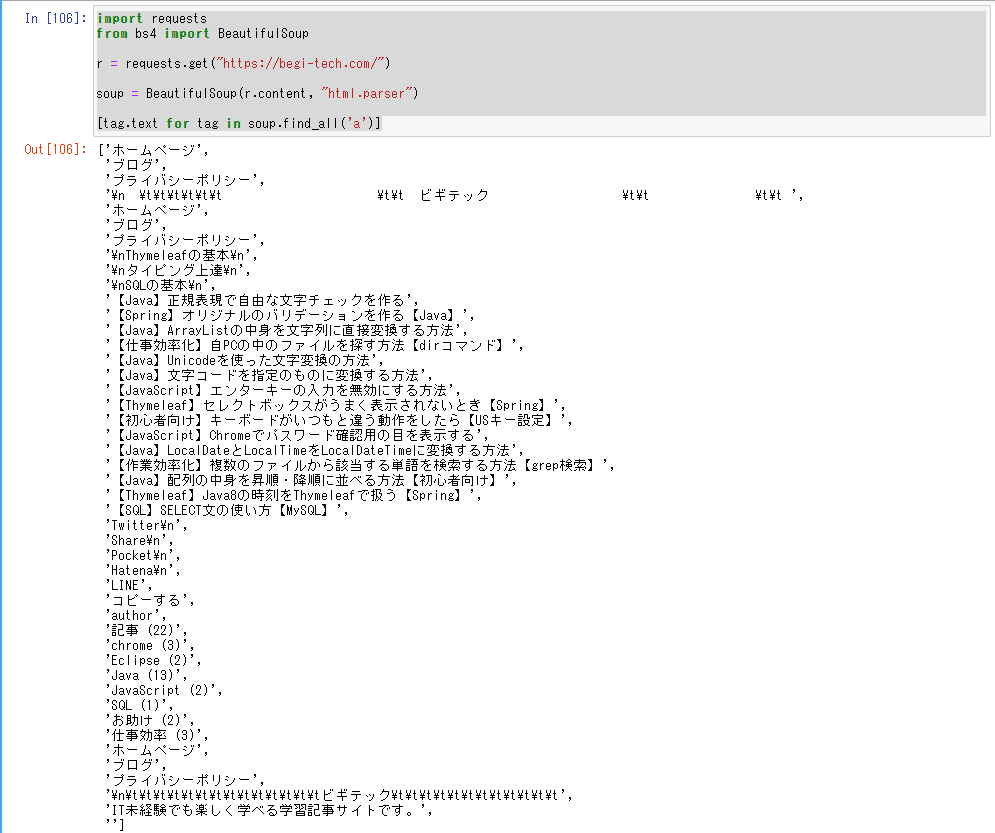
上のようにサイトの実際の情報を取得することができます。
今回はリンクを取得しましたが他にもいろいろな要素を取得することができます。
その際は[tag.text for tag in soup.find_all('a')]の部分を変更してみてください。もちろん複数指定してもできます。
| コード | 意味 |
|---|---|
| soup.find('a') | 1つ目のaタグを取得 |
| soup.find('a').text | タグのテキスト部分のみを取得。他の要素でも.textを付けることで対応可能 |
| soup.find_all('a') | サイト内のaタグを全取得。 |
| [tag.text for tag in soup('a')] | 全取得した場合は結果がリストで帰ってくるので1つずつ表示する必要がありその場合の書き方。 |
| [tag.get('href') for tag in soup('a')] | すべてのaタグのリンクURLを取得。get()の中に要素を指定することで取得ができる。 |
| soup.find(id='id名') | idを指定して情報を取得。 |
| soup.find_all(id='id_名') | id名で全取得。 |
| soup.find(class_='class名') | クラス名で情報を取得。 |
| soup.find_all(class_='class名') | クラス名で情報を全取得。 |
まとめ
今回自分の勉強を兼ねて記事を書いたのでまだまだやりようはあるのですが、まずは基本中の基本を学べたと思います。
今後もPythonは熱い言語だと思うのでスクレイピングや機械学習も積極的に使用していきたいです。